
基于Python的B站数据爬取及可视化
简而言之,网络爬虫就像是一台探索机器,它通过模仿人类浏览网站、点击按钮、查询数据的行为,然后将收集到的信息带回。
分析要爬取的每个字段
打开要爬取的b站网页的开发人员模式,并在元素/element一栏中分析返回的html文件,找到各视频对应的标签
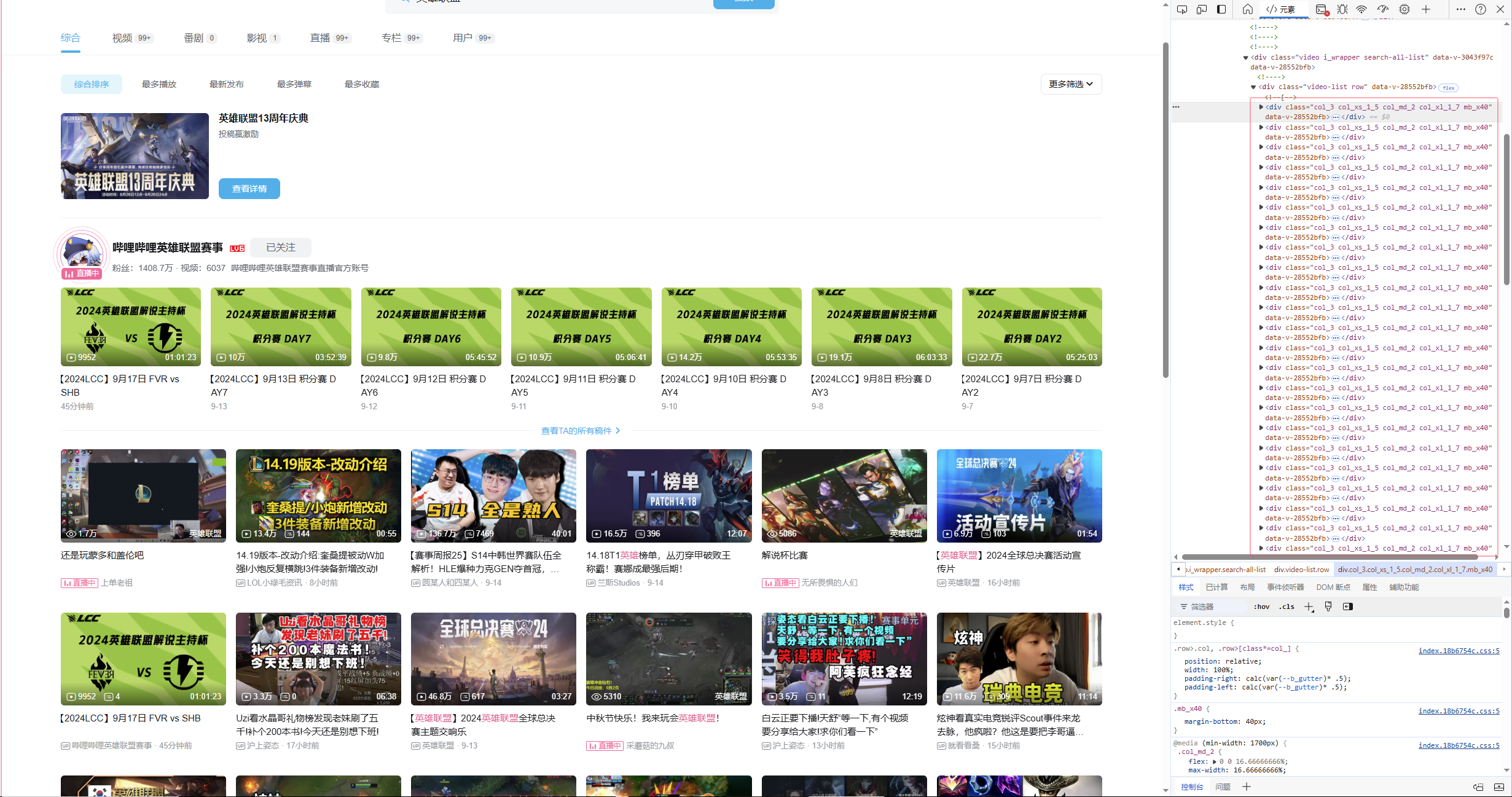
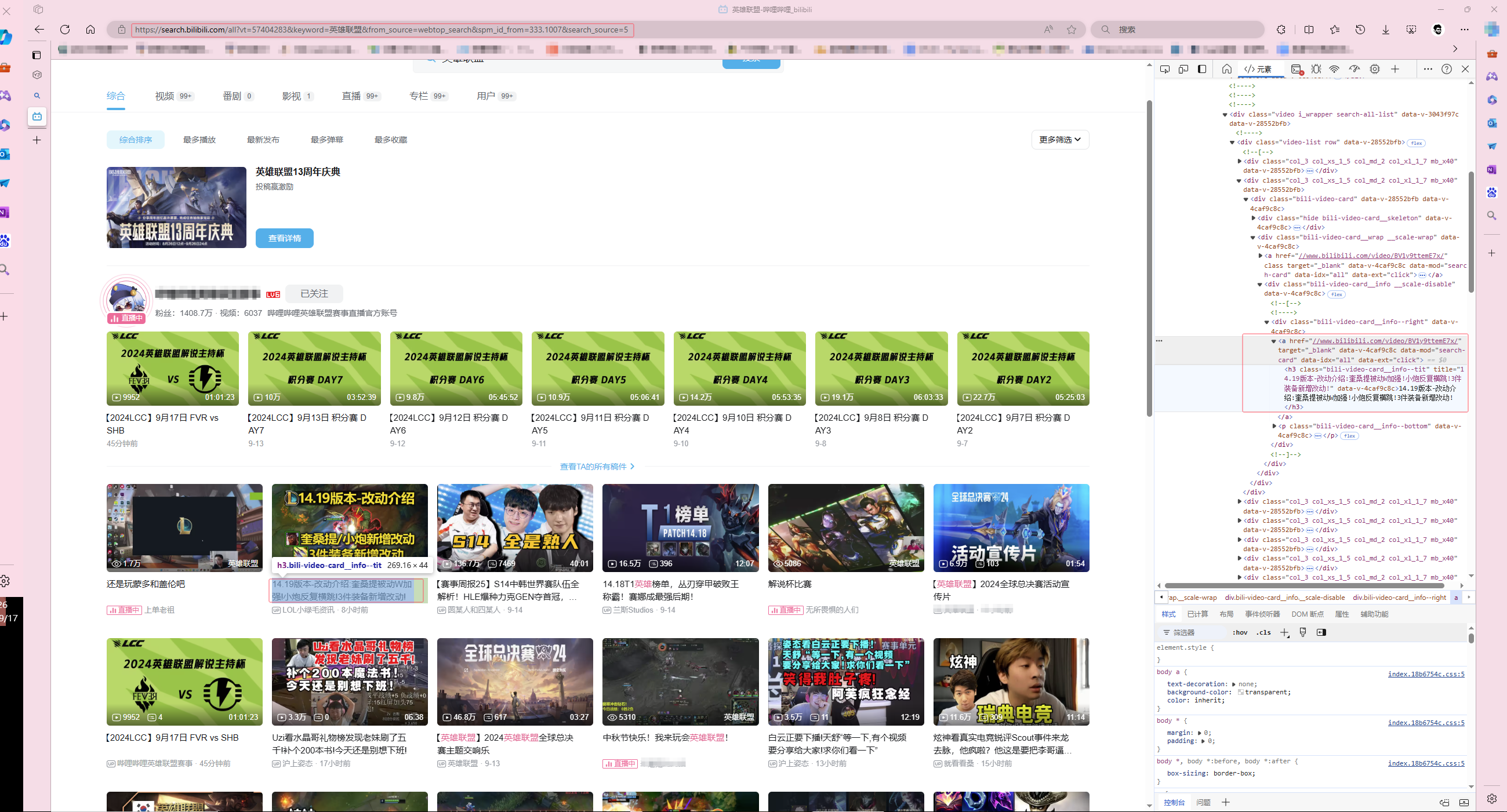
整理可得:
'title': [视频标题], 'view_num': [播放量], 'danmu': [弹幕], 'upload_time': [上传时间], 'up_author': [作者], 'video_url': [视频链接]代码:
#爬取b站视频进行分析
import requests
from bs4 import BeautifulSoup
import time
import random
import pandas as pd
def get_target(keyword, page,saveName):
result = pd.DataFrame()
for i in range(1, page + 1):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36'}
url = 'https://search.bilibili.com/all?keyword={}&page={}&o={}'.format(keyword, i, (i-1)*30)
html = requests.get(url.format(i), headers=headers)
bs = BeautifulSoup(html.content, 'html.parser')
items = bs.find_all('div', class_='video-list-item col_3 col_xs_1_5 col_md_2 col_xl_1_7 mb_x40')
for item in items:
video_url = item.find('a')['href'].replace("//","") # 每个视频的来源地址
title = item.find('h3', class_='bili-video-card__info--tit')['title'] # 每个视频的标题
view_num = item.find_all('span', class_='bili-video-card__stats--item')[0].find('span').text # 每个视频的播放量
danmu = item.find_all('span', class_='bili-video-card__stats--item')[1].find('span').text # 弹幕
upload_time = item.find('span', class_='bili-video-card__info--date').text.replace(" · ","") # 上传日期
up_author = item.find('span', class_='bili-video-card__info--author').text # up主
df = pd.DataFrame({'title': [title], 'view_num': [view_num], 'danmu': [danmu], 'upload_time': [upload_time], 'up_author': [up_author], 'video_url': [video_url]})
result = pd.concat([result, df])
time.sleep(random.random() + 1)
print('已经完成b站第 {} 页爬取'.format(i))
saveName = saveName + ".csv"
result.to_csv(saveName, encoding='utf-8-sig',index=False) # 保存为csv格式的文件
return result
if __name__ == "__main__":
keyword = input("请输入要搜索的关键词:")
page = int(input("请输入要爬取的页数:"))
saveName = input("请输入要保存的文件名:")
get_target(keyword, page,saveName)
运行结果:
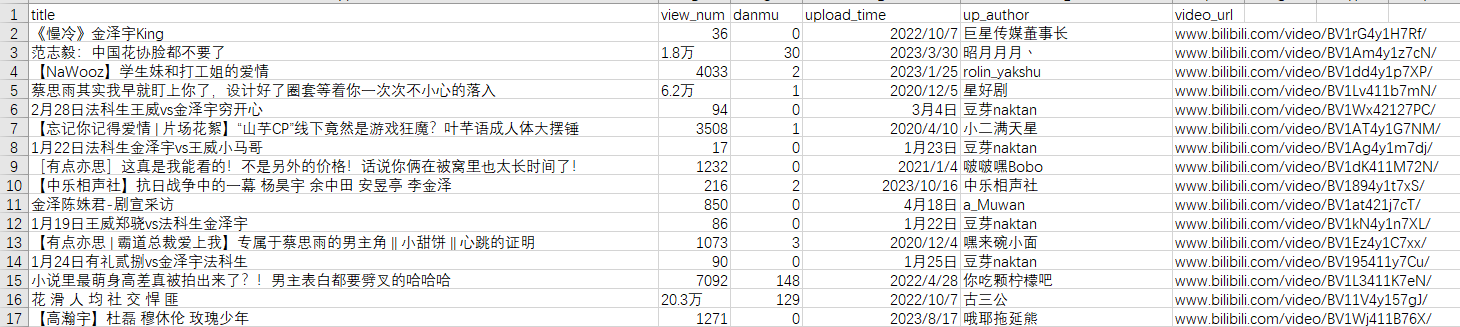
对爬取到的数据进行分析
预处理:
#1.读入数据
import pandas as pd
#设置显示的最大列、宽等参数,消掉打印不完全中间的省略号
pd.set_option('display.max_columns', None)
pd.set_option('display.width', None)
pd.set_option('display.max_colwidth', 1000)
df = pd.read_csv('jzy.csv',header=0,encoding="utf-8-sig")
#print(df.shape) #数据大小(行、列)
#print(df.head()) #数据内容,只打印了头部的前4个信息
#2.数据预处理
import numpy as np
def transform_unit(x_col):
"""
功能:转换数值型变量的单位
"""
# 提取数值
s_num = df[x_col].str.extract('(\d+\.*\d*)').astype('float')
# 提取单位
s_unit = df[x_col].str.extract('([\u4e00-\u9fa5]+)')
s_unit = s_unit.replace('万', 10000).replace(np.nan, 1)
s_multiply = s_num * s_unit
return s_multiply
# 去重
df = df.drop_duplicates()
# 删除列
df.drop('video_url', axis=1, inplace=True)
# 转换单位
df['view_num'] = transform_unit(x_col='view_num')
df['danmu'] = transform_unit(x_col='danmu')
# 筛选时间
df = df[(df['upload_time'] >= '2010-09-01') & (df['title'].astype('str').str.contains('金泽宇'))]
print(df.head())
可视化:
引入jieba包
1)发布数量及播放数量折线图
#发布热度
time_num = df.upload_time.value_counts().sort_index() #time_num中包含的是日期,及每个日期内有多少个视频发布
print(time_num)
#print(time_num.index)
#某天的播放量(https://www.cnblogs.com/zhoudayang/p/5534593.html)
time_view = df.groupby(by=['upload_time'])['view_num'].sum() #如果需要按照列A进行分组,将同一组的列B求和
print(time_view)
# 折线图(不同的图的叠加https://[pyecharts学习笔记]——Grid并行多图、组合图、多 X/Y 轴)
line1 = Line(init_opts=opts.InitOpts(width='1350px', height='750px',background_color='white'))
line1.add_xaxis(time_num.index.tolist())
line1.add_yaxis('发布数量', time_num.values.tolist(),
markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_='min'), #标记最小点及最大点
opts.MarkPointItem(type_='max')]),
# 添加第一个轴,索引为0,(默认也是0)
yaxis_index = 0,
#color = "#d14a61", # 系列 label 颜色,红色
)
line1.add_yaxis('播放总量', time_view.values.tolist(),
markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_='min'),
opts.MarkPointItem(type_='max')]),
yaxis_index=1, # 上面的折线图图默认索引为0,这里设置折线图y 轴索引为1
#color="#5793f3", # 系列 label 颜色蓝色
)
#新加入一个y轴(索引值是1)下方是对其的详细配置
line1.extend_axis(
yaxis=opts.AxisOpts(
name="播放总量", # 坐标轴名称
type_="value", # 坐标轴类型 'value': 数值轴,适用于连续数据。
min_=0, # 坐标轴刻度最小值
max_=int(time_view.max()), # 坐标轴刻度最大值
position="right", # 轴的位置 侧
# 轴线配置
# axisline_opts=opts.AxisLineOpts(
# # 轴线颜色(默认黑色)
# linestyle_opts=opts.LineStyleOpts(color="#5793f3")
# ),
# 轴标签显示格式
#axislabel_opts=opts.LabelOpts(formatter="{value} c"),
)
)
#全局配置(全局配置中默认已经存在一个y轴了(默认索引值是0),要想更改此左侧的y轴必须更改此处的)
line1.set_global_opts(
yaxis_opts=opts.AxisOpts(
name="发布数量",
min_=0,
max_=int(time_num.max()),
position="left",
#offset=80, # Y 轴相对于默认位置的偏移,在相同的 position 上有多个 Y 轴的时候有用。
#轴线颜色
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(color="#d14a61")
),
axislabel_opts=opts.LabelOpts(formatter="{value} ml"),
),
title_opts=opts.TitleOpts(title='王冰冰视频发布热度/播放热度走势图', pos_left='5%'),#标题
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate='45')), #x轴的标签倾斜度为垂直
)
#系列配置项,不显示标签(不会将折线上的每个点的值都在图中显示出来)
line1.set_series_opts(linestyle_opts=opts.LineStyleOpts(width=3),
label_opts=opts.LabelOpts(is_show=False)
)
line1.render("line.html")
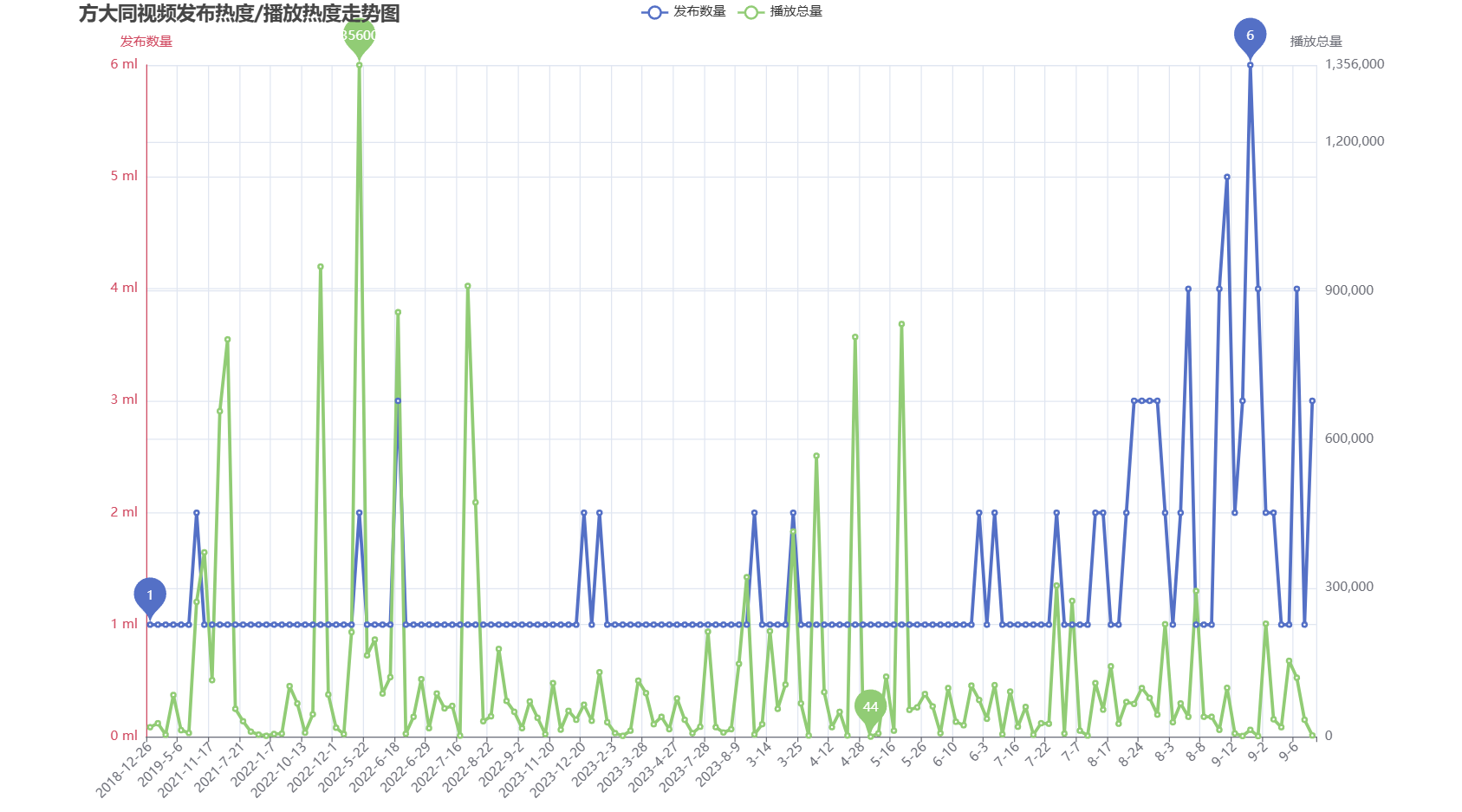
2)B站播放数量最高的前十个视频
#(2)B站播放数量最高的前10个视频(x轴和y轴进行交换)
#进行排序
top_num = df.sort_values(by='view_num',ascending=False) #根据列view_num的值进行排序,并按照降序排列(默认是升序)
print(top_num.head(10)) #打印前十个值,降序的
top10_num=top_num.head(10).sort_values(by='view_num') #将前10个拿出来再按照升序排列,因为后面进行条形图排列,xy轴互换时会将数最大的排在前面
print(top10_num) #打印前十个值,升序的
columns = top10_num.reset_index()['title'].values.tolist() #将某一列的值拿出来做为一个列表
print(columns)
data = top10_num.reset_index()['view_num'].values.tolist() #将某一列的值拿出来做为一个列表
print(data)
bar = (
Bar(init_opts=opts.InitOpts(width="2000px",height="700px")) #此处通过扩大宽度,来将左侧的标题囊括过来
.add_xaxis(columns)
.add_yaxis("播放量", data,
)
.reversal_axis() #此处将x轴与y轴进行互换
.set_global_opts(
title_opts=opts.TitleOpts(title="B站方大同播放数量Top10视频",pos_left='9%'),
)
#系列配置项,将标签位置显示在右侧
.set_series_opts( label_opts=opts.LabelOpts(position="right"))
)
bar.render("bar.html")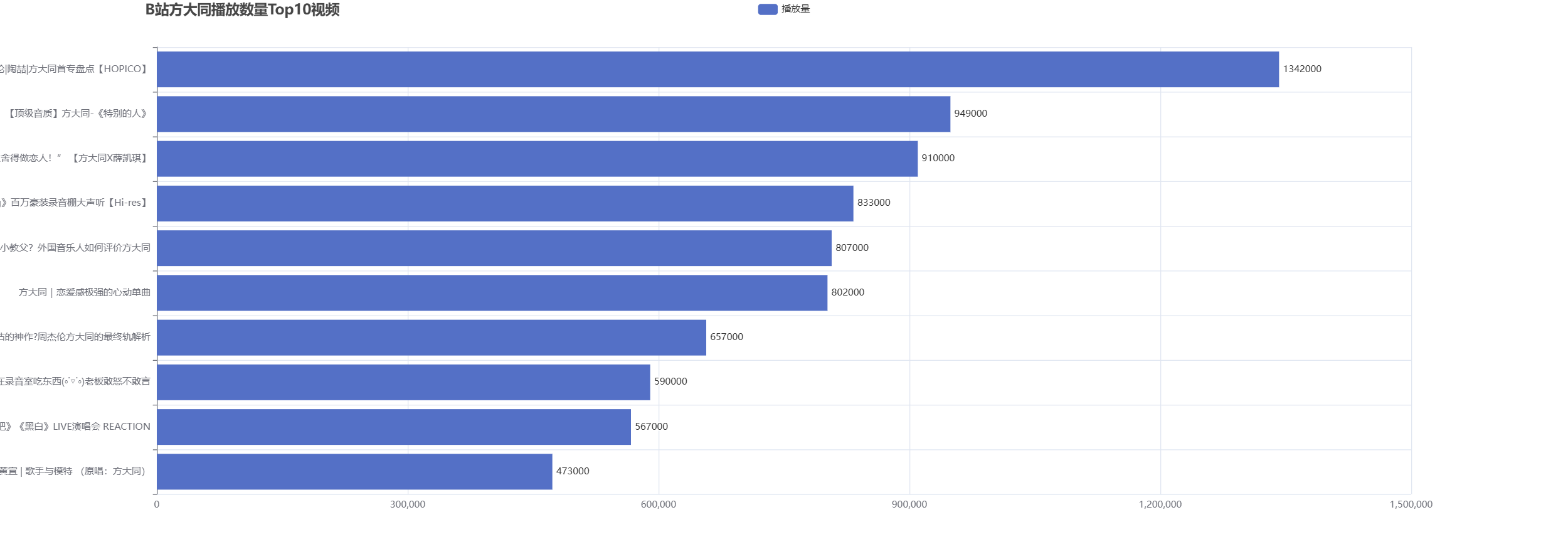
弹幕词云分析
参考链接:https://blog.csdn.net/stormhou/article/details/135350170
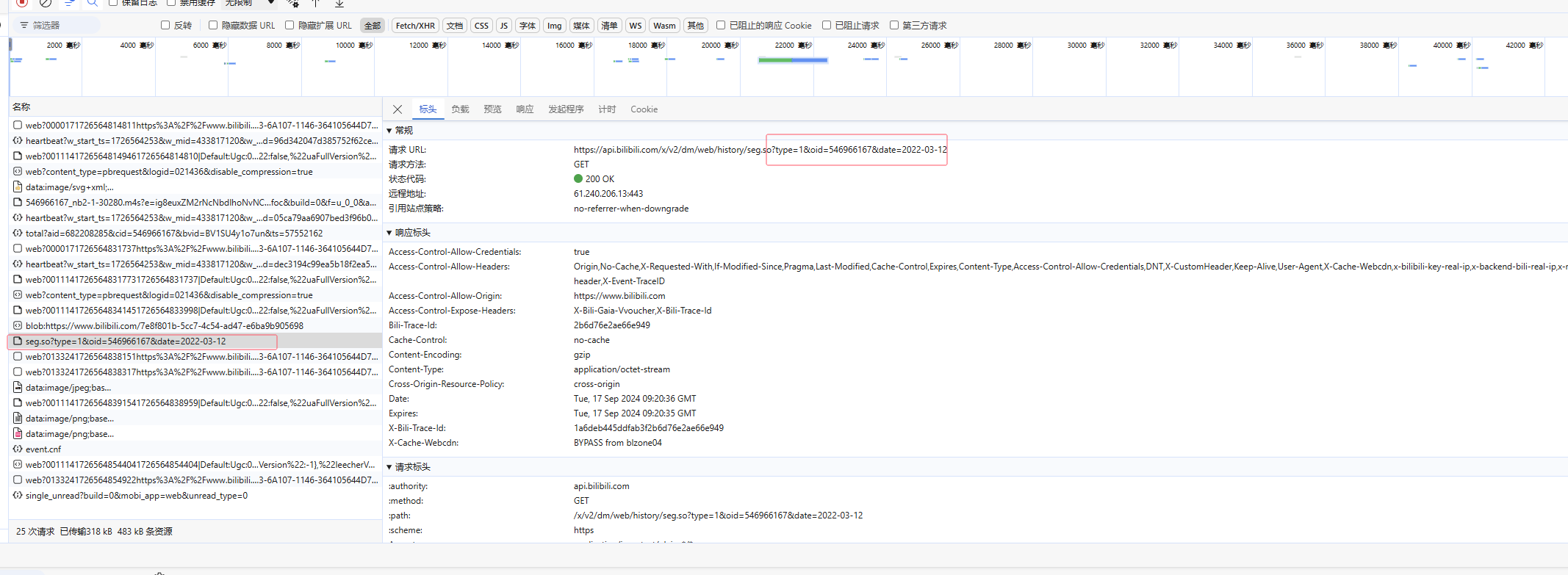
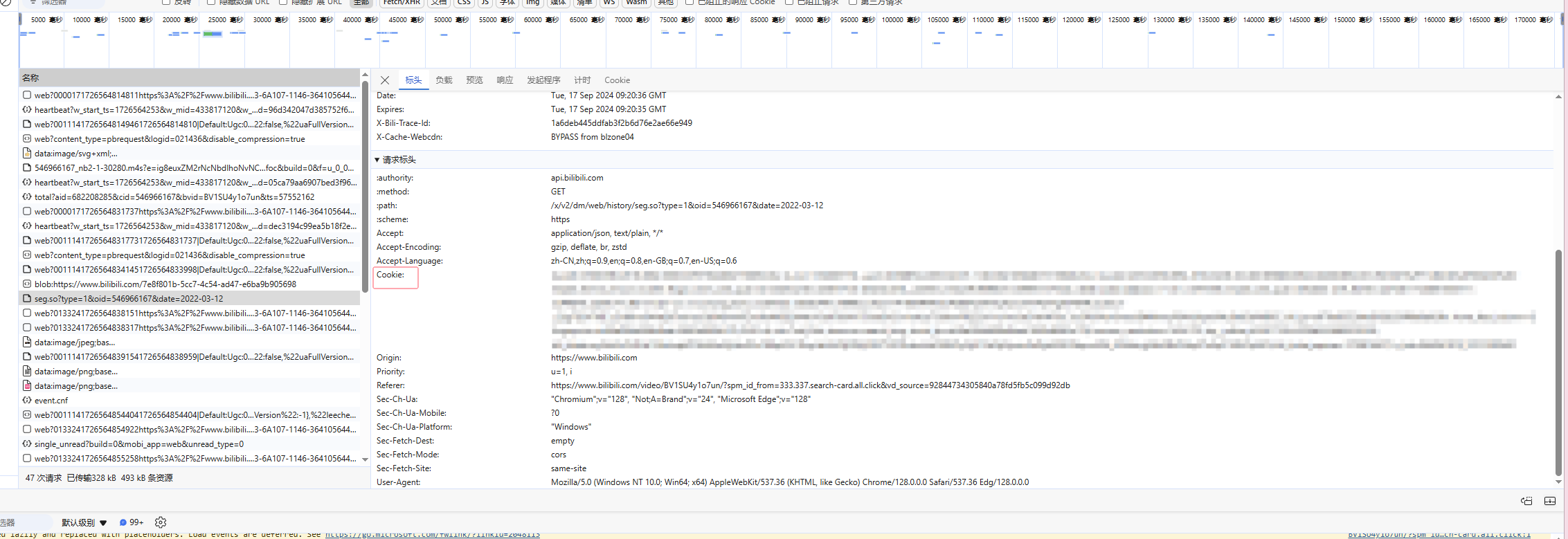
B站的弹幕数据可以使用接口调用,它是以一个固定的url地址+视频的cid+.xml组成的,我们可以找到想要的视频cid替换就可以爬取所有的弹幕了
分析页面,打开任意一个视频播放界面,键盘F12快捷键,点开弹幕列表下的查看历史弹幕,选择一个日期

在开发者工具页面找到oid和cookie并进行替换:
代码:
import requests
import re
import datetime
import pandas as pd
# content_list存放所有弹幕
content_list = []
# 爬取开始日期和结束日期范围内的弹幕
begin = datetime.date(2022, 3, 11)
end = datetime.date(2022, 5, 11)
for i in range((end - begin).days + 1):
day = begin + datetime.timedelta(days=i)
url = f'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid=546966167&date={day}'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'cookie': '替换成自己的'
}
response = requests.get(url=url, headers=headers)
response.encoding = 'utf-8'
temp_list = re.findall('[\u4e00-\u9fa5]+', response.text)
content_list.extend(temp_list)
print("爬取", day, "日弹幕,获取到:", len(temp_list), "条弹幕,已经增加到总列表。总列表共有", len(content_list),
"条弹幕。")
print(content_list)
comments_dict = {'comments': content_list} # 定义一个字典
df = pd.DataFrame(comments_dict)
df.to_csv('danmu.csv', encoding='utf-8-sig') # 保存为csv格式的文件运行结果:

生成词云:
#读取数据
import pandas as pd
data = pd.read_csv('danmu.csv',header=0,encoding="utf-8-sig")
print(data.shape[0]) #数量
print(data.head()) #数据内容,只打印了头部的前4个信息
#词云的可视化
import jieba #分词(将一个句子分成很多个词语)
from matplotlib import pyplot as plt #绘图,数据可视化,点状图、柱状图等科学绘图,和echarts不同,不是直接用于网站,而是生成图片
from wordcloud import WordCloud #词云,形成有遮罩效果的
from PIL import Image #用来做图像处理的(官方默认)
import numpy as np #矩阵运算
#分词
#词云是按照词来进行统计的,这个使用jieba自动进行词频统计
text = ''.join(data['comments']) #此处将所有的评论进行了整合连成一个字符串
print(text)
#cut = jieba.cut(text) #将一个字符串进行分割
words = list(jieba.cut(text))
ex_sw_words = []
#下方是对目前的一些字符串进行筛选,将一些没有意义的词语进行清除
stop_words = [x.strip() for x in open('stopwords.txt', encoding="utf-8")]
for word in words:
if len(word) > 1 and (word not in stop_words):
ex_sw_words.append(word)
#print(ex_sw_words)
#print(cut) #返回cut是一个对象<generator object Tokenizer.cut at 0x000002644AAECF48>
string = ' '.join(ex_sw_words) #此处将其对象cut变成字符串,可在下方显示,#' '.join(cut) 以指定字符串空格‘ ’作为分隔符,将 cut 中所有的元素(的字符串表示)合并为一个新的字符串
print(string) #此时可以打印如下
print(len(string)) #个词,要对这些词进行统计
#可以自己找图建议轮廓清晰
img = Image.open(r'10.png') #打开遮罩图片
img_arry = np.array(img) #将图片转换为数组,有了数组即可做词云的封装了
from matplotlib import colors
#建立颜色数组,可更改颜色
color_list=['#CD853F','#DC143C','#00FF7F','#FF6347','#8B008B','#00FFFF','#0000FF','#8B0000','#FF8C00',
'#1E90FF','#00FF00','#FFD700','#008080','#008B8B','#8A2BE2','#228B22','#FA8072','#808080']
#调用
colormap=colors.ListedColormap(color_list)
wc = WordCloud(
background_color='white', #背景必须是白色
mask = img_arry, #传入遮罩的图片,必须是数组
font_path = "msyh.ttc", #设置字体,(字体如何找,可以在C:/windows/Fonts中找到名字)
colormap=colormap, # 设置文字颜色
max_font_size=150, # 设置字体最大值
random_state=18 # 设置有多少种随机生成状态,即有多少种配色方案
)
#
wc.generate_from_text(string) #从哪个文本生成wc,这个文本必须是切好的词
#绘制图片
fig = plt.figure(1) #1表示第一个位置绘制
plt.imshow(wc) #按照wc词云的规格显示
plt.axis('off') #是否显示坐标轴,不显示(单一图片)
#plt.show() #显示生成的词云图片
plt.savefig(r'cloud.jpg',dpi=400) #输出词云图片到文件,默认清晰度是400,这里设置500可能有点高,注意此处要保存,show()方法就得注释词云图片:





