
图像去雾在计算机视觉中不像目标检测和语义分割这样热门,但随着CNN模型流行的今天,图像去雾算法也经过了一轮非常大的进步。
整体来说,图像去雾算法可以分为这么几类
基于图像增强的去雾算法。基于图像增强的去雾算法出发点是尽量去除图像噪声,提高图像对比度,从而恢复出无雾清晰图像。代表性方法有:直方图均衡化(HLE)、自适应直方图均衡化(AHE)、限制对比度自适应直方图均衡化(CLAHE) 、Retinex算法、小波变换、同态滤波等等。
基于图像复原的去雾算法。这一系列方法基本是基于大气退化模型,进行响应的去雾处理。代表性算法有:来自何凯明博士的暗通道去雾算法(CVPR 2009最佳论文)、基于导向滤波的暗通道去雾算法、Fattal的单幅图像去雾算法(Single image dehazing) 、Tan的单一图像去雾算法(Visibility in bad weather from a single image) 、Tarel的快速图像恢复算法(Fast visibility restoration from a single color or gray level image) 、贝叶斯去雾算法(Single image defogging by multiscale depth fusion),基于大气退化模型的去雾效果普遍好于基于图像增强的去雾算法。
基于深度学习的去雾算法。由于CNN近年在一些任务上取得了较大的进展,去雾算法自然也有大量基于CNN的相关工作。这类方法是主要可以分为两类,第一类仍然是于大气退化模型,利用神经网络对模型中的参数进行估计,早期的方法大多数是基于这种思想。第二类则是利用输入的有雾图像,直接输出得到去雾后的图像,也即是深度学习中常说的end2end(端到端)。
在这里,我主要介绍两种方法,一种是基于暗通道的先验去雾,另一种是基于深度学习的去雾
基于暗通道的先验去雾
实验目的
户外场景的影像常受到大气中颗粒物和水滴的影响,如雾、霾和烟。这些现象源于大气的吸收和散射作用,导致摄像机接收到的辐射强度沿视线逐渐衰减,从而降低图像的对比度和色彩保真度。因此,对图像进行去雾处理具有多个关键作用:
对比度与色彩校正的提升:去雾能够显著改善图像的对比度和色彩准确性,从而提高图像质量。
视觉算法性能的优化:许多图像处理算法假设输入图像质量良好,去雾处理可以有效提升这些算法的性能。
深度估计的辅助:散射率图与图像深度密切相关,估计大气光的散射率有助于深度信息的推断,这在多种应用中具有重要价值。
此项目首先对大气散射模型进行了深入分析,对入射光衰减和大气光成像进行了数学建模,得出了带雾图像的形成模型。基于此模型,可以推导出了图像去雾模型,并利用该模型成功从带雾图像中恢复出清晰图像。
实验原理
大气散射模型
成像设备在获取现实场景图像时,受到目标物体、太阳光和大气条件的综合影响。正如图中所示,目标物体的光线在传播过程中,由于大气中的杂质会发生衰减。图中两种颜色分别表示反射光的衰减和大气杂光的散射,它们共同影响最终的成像结果。
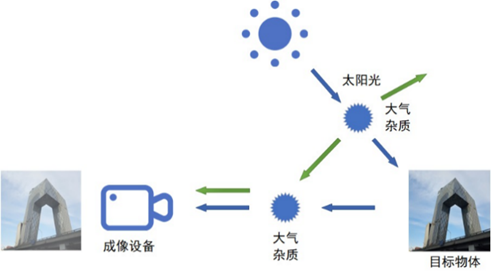
入射光衰减模型
入射光线在目标物体表面反射后,反射光在传播过程中与空气中的微粒发生碰撞和散射。从图中可以看出,部分反射光经过散射后未能到达成像设备。这样传播到其他位置的光线即为入射光的衰减。反射光的衰减程度与传播的空间距离密切相关,距离越大,发生散射的几率越高,相应的光线衰减也越显著,从而导致捕获的图像信息模糊不清。
这部分数学模型可以表达为:

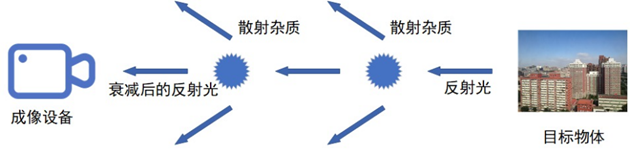
大气光成像模型
除了反射光可以进入到成像设备外,大气中还有很多杂质光因为各种散射进入到成像设备中,即上图中的绿色箭头部分
这一部分数学模型可以表达为:

雾图形成模型及简化
将上面的两个模型内容进行叠加,可以得到雾图形成的模型

去雾模型
通过将雾图形成模型进行简单变换即可得到去雾公式

传统方法中通过引入先验来减少参数量,例如暗通道先验

暗通道先验
在绝大多数非天空的局部区域中,某一些像素总会有至少一个颜色通道具有很低的值。换言之,该区域光强度的最小值是个很小的数,因此暗通道的数学定义为:

对于无雾图,他应该是符合暗通道先验的,对图片求暗通道的化,暗通道整体应该偏黑,对于带雾图则相反

全局大气光A的估计算法:
1. 从暗通道图中取前0.1%最亮的像素;
2. 在这些像素对应的位置中,在原始有雾图像I中寻找具有最高亮度像素的值,作为全局大气光A
主要涉及的python函数

程序实现
导入库
import cv2
import numpy as np
import matplotlib.pyplot as plt
import math
from skimage.metrics import structural_similarity as sk_cpt_ssimcv2: OpenCV库,用于图像处理。
numpy: 用于数值计算。
matplotlib.pyplot: 用于绘图。
math: 用于数学计算。
skimage.metrics.structural_similarity: 用于计算结构相似性指数(SSIM)。
引导滤波器
def guided_filter(I,p,win_size,eps):
mean_I = cv2.blur(I,(win_size,win_size))
mean_p = cv2.blur(p,(win_size,win_size))
corr_I = cv2.blur(I*I,(win_size,win_size))
corr_Ip = cv2.blur(I*p,(win_size,win_size))
var_I = corr_I-mean_I*mean_I
cov_Ip = corr_Ip - mean_I*mean_p
a = cov_Ip/(var_I+eps)
b = mean_p-a*mean_I
mean_a = cv2.blur(a,(win_size,win_size))
mean_b = cv2.blur(b,(win_size,win_size))
q = mean_a*I + mean_b
return qguided_filter 函数实现了引导滤波器,用于平滑图像并保留边缘信息。
I 是引导图像,p 是输入图像,win_size 是窗口大小,eps 是正则化参数。
获得最小通道
def get_min_channel(img):
return np.min(img, axis=2)get_min_channel 函数返回图像的最小通道值,用于计算暗通道。
最小值滤波器
def min_filter(img, r):
kernel = np.ones((2 * r - 1, 2 * r - 1))
return cv2.erode(img, kernel)min_filter 函数实现最小值滤波器,使用腐蚀操作来替代。
获得大气光值
def get_A(img_haze, dark_channel, bins_l):
hist, bins = np.histogram(dark_channel, bins=bins_l)
d = np.cumsum(hist) / float(dark_channel.size)
threshold = 0
for i in range(bins_l - 1, 0, -1):
if d[i] <= 0.999:
threshold = i
break
A = img_haze[dark_channel >= bins[threshold]].max()
show = np.copy(img_haze)
show[dark_channel >= bins[threshold]] = 0, 0, 255
cv2.imwrite('./most_haze_opaque_region_2.jpg', show * 255)
return Aget_A 函数计算大气光值 A,用于去雾。
通过直方图和累积分布函数确定阈值,选择暗通道中亮度最高的区域作为大气光值。
获得大气透射率
def get_t(img_haze, A, t0=0.1, w=0.95):
out = get_min_channel(img_haze)
out = min_filter(out, r=7)
t = 1 - w * out / A
t = np.clip(t, t0, 1)
return tget_t 函数计算透射率 t,用于去雾。
w 是一个权重参数,用于保留远处的雾。
计算峰值信噪比PSNR
def PSNR(target, ref):
target = target / 255.0
ref = ref / 255.0
MSE = np.mean((target - ref) ** 2)
if MSE < 1e-10:
return 100
MAXI = 1
PSNR = 20 * math.log10(MAXI / math.sqrt(MSE))
return PSNRPSNR 函数计算去雾图像与原始图像之间的峰值信噪比。
主程序
if __name__ == '__main__':
I = cv2.imread('test_2.jpg') / 255.0
dark_channel = get_min_channel(I)
dark_channel_1 = min_filter(dark_channel, r=7)
cv2.imwrite("./dark_channel_2.jpg", dark_channel_1 * 255)
A = get_A(I, dark_channel_1, bins_l=2000)
t = get_t(I, A)
t = guided_filter(dark_channel, t, 81, 0.001)
t = t[:, :, np.newaxis].repeat(3, axis=2)
J = (I - A) / t + A
J = np.clip(J, 0, 1)
J = J * 255
J = np.uint8(J)
cv2.imwrite("./result_2.jpg", J)
PSNR = PSNR(J, I * 255)
print(f"PSNR:{PSNR}")
ssim = sk_cpt_ssim(J, I * 255, win_size=11, data_range=255, multichannel=True)
print(f"ssim:{ssim}")读取输入图像 test_2.jpg,并将其归一化。
计算暗通道并进行最小值滤波。
计算大气光值 A 和透射率 t。
使用引导滤波器平滑透射率。
计算去雾后的图像 J。
保存去雾后的图像,并计算去雾图像与原始图像之间的 PSNR 和 SSIM 值。
基于AOD-net的深度学习去雾
实验原理
原始大气散射模型
传统的去雾方法主要是基于大气散射模型进行,除了估计全局大气光强之外,实现雾去除的关键是恢复透射率矩阵,但是估计并不总是准确的,一些常见的预处理如引导滤波 或soft matting会进一步扭曲模糊图像生成过程,导致次优的恢复性能,并且全局大气光强和透射率矩阵分开估计导致最后将两者联合的时候有时会出现问题
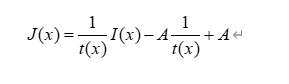
联合训练
为了从带雾图像中恢复干净的场景,估计准确的介质透射图是关键,物理模型可以以“更加端到端”的方式制定,其所有参数都在一个统一模型中估计,因此将公式进行变换,构建一个新的参数图K来包括全局大气光和介质投射图,引入了变换后的大气散射模型。
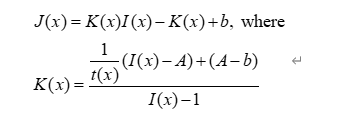
通过将全局大气光和介质投射图进行联合训练,可以使用类似MSE损失直接对重建后的干净图片进行最小化损失的训练操作
网络结构
构建一个全卷积的网络对K进行估计,然后使用K和变换后的大气散射模型来恢复出干净的图像

主要涉及的python函数
torchvision.transforms.Compose(transforms)
图片输入网络需要进行预处理操作,例如转换为Tensor类型,进行标准化操作,该函数将多个变换组合在一起,一起作用于输入图片中。
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
对由多个输入平面组成的输入信号应用2D卷积,可以描述为下列过程:
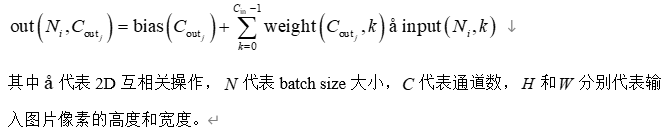
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1, verbose=False)
每个step_size的epochs用gamma衰减每个参数组的学习率。请注意,这种衰减可能与来自该调度程序外部的其他学习率变化同时发生。 当last_epoch=-1时,设置初始学习率lr为lr,在本实验中使用Adam优化器对参数进行优化操作
程序设计
环境要求
Python 3.6, Pytorch 0.4.0和其他一些通用Python库
合成带雾图片
通过原始大气散射模型来创建合成的带雾图像,使用来自 indoor NYU2 Depth Database的真实无雾室内图片和深度图来生成带雾图片。设在[0.6,1.0]之间设置不同全局大气光值,并选择不同参数生成带雾图片,对于 NYU2 数据库,使用27256 张图像作为训练集,3170 张不同的图片作为测试集。
导入库
from __future__ import division
import argparse
import math
import os
import pdb
import pickle
import random
import shutil
import sys
import time
from math import log10
from random import uniform
import matplotlib.cm as cm
import matplotlib.patches as patches
import matplotlib.pyplot as plt
import numpy as np
import PIL
import scipy
import scipy.io as sio
import scipy.ndimage.interpolation
from PIL import Image
import h5py
sys.path.append("./mingqingscript")
plt.ion()from future import division: 确保在Python 2.x中使用Python 3.x的除法行为。
argparse: 用于解析命令行参数。
math, os, pdb, pickle, random, shutil, sys, time, log10, uniform: 各种标准库模块。
matplotlib.cm, matplotlib.patches, matplotlib.pyplot: 用于绘图。
numpy, PIL, scipy, scipy.io, scipy.ndimage.interpolation: 用于科学计算和图像处理。
h5py: 用于处理HDF5格式的数据。
sys.path.append("./mingqingscript"): 将自定义脚本目录添加到Python路径中。
plt.ion(): 开启交互式绘图模式。
定义函数
def array2PIL(arr, size):
mode = 'RGBA'
arr = arr.reshape(arr.shape[0] * arr.shape[1], arr.shape[2])
if len(arr[0]) == 3:
arr = np.c_[arr, 255 * np.ones((len(arr), 1), np.uint8)]
return Image.frombuffer(mode, size, arr.tostring(), 'raw', mode, 0, 1)array2PIL 函数将NumPy数组转换为PIL图像对象。
mode = 'RGBA': 设置图像模式为RGBA。
arr = arr.reshape(arr.shape[0] * arr.shape[1], arr.shape[2]): 将数组重塑为一维数组。
if len(arr[0]) == 3: 如果数组是三通道的,添加一个全为255的alpha通道。
return Image.frombuffer(...): 返回从缓冲区创建的PIL图像对象。
解析命令行参数
parser = argparse.ArgumentParser()
parser.add_argument('--nyu', type=str, required=True, help='path to nyu_depth_v2_labeled.mat')
parser.add_argument('--dataset', type=str, required=True, help='path to synthesized hazy images dataset store')
args = parser.parse_args()
print(args)使用 argparse 解析命令行参数。
--nyu: NYU Depth V2数据集的路径。
--dataset: 合成雾图像数据集的存储路径。
读取NYU Depth V2数据集
index = 1
nyu_depth = h5py.File(args.nyu + '/nyu_depth_v2_labeled.mat', 'r')
directory = args.dataset + '/train'
saveimgdir = args.dataset + '/demo'
if not os.path.exists(directory):
os.makedirs(directory)
if not os.path.exists(saveimgdir):
os.makedirs(saveimgdir)
image = nyu_depth['images']
depth = nyu_depth['depths']
img_size = 224打开NYU Depth V2数据集文件。
创建保存合成雾图像的目录。
读取图像和深度数据。
img_size = 224: 设置图像大小为224x224。
生成合成雾图像
total_num = 0
plt.ion()
for index in range(1445):
index = index
gt_image = (image[index, :, :, :]).astype(float)
gt_image = np.swapaxes(gt_image, 0, 2)
gt_image = scipy.misc.imresize(gt_image, [480, 640]).astype(float)
gt_image = gt_image / 255
gt_depth = depth[index, :, :]
maxhazy = gt_depth.max()
minhazy = gt_depth.min()
gt_depth = (gt_depth) / (maxhazy)
gt_depth = np.swapaxes(gt_depth, 0, 1)
for j in range(7):
for k in range(3):
#beta
bias = 0.05
temp_beta = 0.4 + 0.2*j
beta = uniform(temp_beta-bias, temp_beta+bias)
tx1 = np.exp(-beta * gt_depth)
#A
abias = 0.1
temp_a = 0.5 + 0.2*k
a = uniform(temp_a-abias, temp_a+abias)
A = [a,a,a]
m = gt_image.shape[0]
n = gt_image.shape[1]
rep_atmosphere = np.tile(np.reshape(A, [1, 1, 3]), [m, n, 1])
tx1 = np.reshape(tx1, [m, n, 1])
max_transmission = np.tile(tx1, [1, 1, 3])
haze_image = gt_image * max_transmission + rep_atmosphere * (1 - max_transmission)
total_num = total_num + 1
scipy.misc.imsave(saveimgdir+'/haze.jpg', haze_image)
scipy.misc.imsave(saveimgdir+'/gt.jpg', gt_image)
h5f=h5py.File(directory+'/'+str(total_num)+'.h5','w')
h5f.create_dataset('haze',data=haze_image)
h5f.create_dataset('gt',data=gt_image)total_num = 0: 初始化合成图像的计数器。
plt.ion(): 开启交互式绘图模式。
遍历NYU Depth V2数据集中的图像和深度数据。
对每张图像和深度数据,生成7x3种不同的合成雾图像。
beta 和 A 是随机生成的参数,用于控制雾的浓度和大气光值。
tx1 = np.exp(-beta * gt_depth): 计算透射率。
haze_image = gt_image max_transmission + rep_atmosphere (1 - max_transmission): 生成合成雾图像。
保存合成雾图像和对应的原始图像到指定目录。
将合成雾图像和原始图像保存到HDF5文件中。
随机挑选图片组成测试集和训练集
import argparse
import os
import random
import shutil
parser = argparse.ArgumentParser()
parser.add_argument('--trainroot', type=str, required=True, help='path to train directory')
parser.add_argument('--valroot', type=str, required=True, help='path to validation directory')
args = parser.parse_args()
print(args)
train = args.trainroot
val = args.valroot
if not os.path.exists(val):
os.makedirs(val)
for i in range(250):
a = random.choice(os.listdir(train))
shutil.move((train+'/'+a), (val+'/'+a))从训练数据集中随机选择250个文件,并将它们移动到验证数据集中。通过这种方式,可以将数据集划分为训练集和验证集,以便在机器学习模型训练过程中进行验证。
去雾网络模型构建
模型使用五层的全卷积神经网络对参数图K进行估计,通过设置不同的卷积核尺寸对图片进行滤波操作,每次卷积后不改变图片的分辨率,将不同层的结果进行跳层的连接,这样的多尺度设计捕捉了不同尺度的特征,中间连接也弥补了卷积过程中的信息丢失。
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class AODnet(nn.Module):
def __init__(self):
super(AODnet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=1)
self.conv2 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(in_channels=6, out_channels=3, kernel_size=5, padding=2)
self.conv4 = nn.Conv2d(in_channels=6, out_channels=3, kernel_size=7, padding=3)
self.conv5 = nn.Conv2d(in_channels=12, out_channels=3, kernel_size=3, padding=1)
self.b = 1
def forward(self, x):
x1 = F.relu(self.conv1(x))
x2 = F.relu(self.conv2(x1))
cat1 = torch.cat((x1, x2), 1)
x3 = F.relu(self.conv3(cat1))
cat2 = torch.cat((x2, x3),1)
x4 = F.relu(self.conv4(cat2))
cat3 = torch.cat((x1, x2, x3, x4),1)
k = F.relu(self.conv5(cat3))
if k.size() != x.size():
raise Exception("k, haze image are different size!")
output = k * x - k + self.b
return F.relu(output) 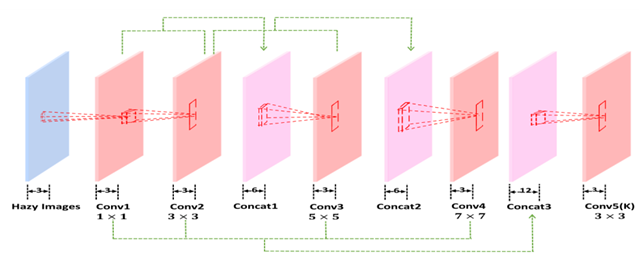
网络模型训练
在训练过程中,使用高斯随机变量初始化权重。利用 ReLU 作为激活函数。 动量和衰减参数分别设置为 0.9 和 0.0001。采用简单的均方误差 (MSE) 损失函数,将去雾后的图片和原始的干净图片之间进行比较,相较于传统方法来说,基于深度学习的去雾方法不仅提高了 PSNR,还提高了 SSIM 和视觉质量。
网络模型需要大约 10 个训练 epoch 才能收敛,并且通常在 10 个 epoch 后表现得足够好,在训练的时候需要指定训练集和测试集的路径
导入库
import argparse
import os
import random
import torch
import torch.backends.cudnn as cudnn
import torch.nn as nn
import torch.nn.functional as F
import torch.nn.parallel
import torch.optim as optim
import torchvision.utils as vutils
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from model import AODnetargparse: 用于解析命令行参数。
os, random: 用于操作系统交互和随机数生成。
torch, torch.backends.cudnn, torch.nn, torch.nn.functional, torch.nn.parallel, torch.optim, torchvision.utils: PyTorch相关库,用于构建和训练神经网络。
torch.autograd.Variable: 用于自动求导。
torch.utils.data.DataLoader: 用于加载数据。
torchvision.datasets, torchvision.transforms: 用于数据集和数据预处理。
model.AODnet: 自定义的去雾网络模型。
解析命令行参数
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', required=False, default='pix2pix', help='')
parser.add_argument('--dataroot', required=True, help='path to trn dataset')
parser.add_argument('--valDataroot', required=True, help='path to val dataset')
parser.add_argument('--valBatchSize', type=int, default=32, help='input batch size')
parser.add_argument('--cuda', action='store_true', help='use cuda?')
parser.add_argument('--lr', type=float, default=1e-4, help='Learning Rate. Default=1e-4')
parser.add_argument('--threads', type=int, default=4, help='number of threads for data loader to use, if Your OS is window, please set to 0')
parser.add_argument('--exp', default='pretrain', help='folder to model checkpoints')
parser.add_argument('--printEvery', type=int, default=50, help='number of batches to print average loss ')
parser.add_argument('--batchSize', type=int, default=32, help='training batch size')
parser.add_argument('--epochSize', type=int, default=840, help='number of batches as one epoch (for validating once)')
parser.add_argument('--nEpochs', type=int, default=10, help='number of epochs for training')
args = parser.parse_args()
print(args)使用 argparse 解析命令行参数。
--dataset: 数据集名称,默认为 pix2pix。
--dataroot: 训练数据集的路径。
--valDataroot: 验证数据集的路径。
--valBatchSize: 验证数据集的批量大小,默认为32。
--cuda: 是否使用CUDA加速。
--lr: 学习率,默认为 1e-4。
--threads: 数据加载器的线程数,默认为4。
--exp: 模型检查点的保存目录,默认为 pretrain。
--printEvery: 每多少个批次打印一次平均损失,默认为50。
--batchSize: 训练批量大小,默认为32。
--epochSize: 每个epoch的批次数,默认为840。
--nEpochs: 训练的epoch数,默认为10。
设置随机种子
args.manualSeed = random.randint(1, 10000)
random.seed(args.manualSeed)
torch.manual_seed(args.manualSeed)
torch.cuda.manual_seed_all(args.manualSeed)
print("Random Seed: ", args.manualSeed)设置随机种子以确保实验的可重复性。
数据加载器
def getLoader(datasetName, dataroot, batchSize, workers,
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5), split='train', shuffle=True, seed=None):
if datasetName == 'pix2pix':
from datasets.pix2pix import pix2pix as commonDataset
import transforms.pix2pix as transforms
if split == 'train':
dataset = commonDataset(root=dataroot,
transform=transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean, std),
]),
seed=seed)
else:
dataset = commonDataset(root=dataroot,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean, std),
]),
seed=seed)
dataloader = torch.utils.data.DataLoader(dataset,
batch_size=batchSize,
shuffle=shuffle,
num_workers=int(workers))
return dataloader
trainDataloader = getLoader(args.dataset,
args.dataroot,
args.batchSize,
args.threads,
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5),
split='train',
shuffle=True,
seed=args.manualSeed)
valDataloader = getLoader(args.dataset,
args.valDataroot,
args.valBatchSize,
args.threads,
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5),
split='val',
shuffle=False,
seed=args.manualSeed)getLoader 函数用于创建数据加载器。
根据数据集名称和分割类型(训练或验证),加载数据集并应用相应的数据增强和归一化。
创建训练和验证数据加载器。
构建模型
print('===> Building model')
net = AODnet()
if args.cuda:
net = net.cuda()创建 AODnet 模型实例。
如果启用了CUDA,将模型移动到GPU上。
损失函数和优化器
criterion = torch.nn.MSELoss()
if args.cuda:
criterion = criterion.cuda()
optimizer = torch.optim.Adam(net.parameters(), lr=args.lr, weight_decay=0.0001)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=53760, gamma=0.5)定义均方误差(MSE)损失函数。
如果启用了CUDA,将损失函数移动到GPU上。
使用Adam优化器,并设置学习率和权重衰减。
使用 StepLR 学习率调度器,每53760步将学习率减半。
训练和验证过程
def train(epoch):
net.train()
epoch_loss = 0
for iteration, batch in enumerate(trainDataloader, 0):
varIn, varTar = Variable(batch[0]), Variable(batch[1])
varIn, varTar = varIn.float(), varTar.float()
if args.cuda:
varIn = varIn.cuda()
if args.cuda:
varTar = varTar.cuda()
optimizer.zero_grad()
loss = criterion(net(varIn), varTar)
epoch_loss += loss.data[0]
loss.backward()
optimizer.step()
if iteration%args.printEvery == 0:
print("===> Epoch[{}]({}/{}): Avg. Loss: {:.4f}".format(epoch, iteration+1, len(trainDataloader), epoch_loss/args.printEvery))
epoch_loss = 0
def validate():
net.eval()
avg_mse = 0
for _, batch in enumerate(valDataloader, 0):
varIn, varTar = Variable(batch[0]), Variable(batch[1])
varIn, varTar = varTar.float(), varIn.float()
if args.cuda:
varIn = varIn.cuda()
if args.cuda:
varTar = varTar.cuda()
prediction = net(varIn)
mse = criterion(prediction, varTar)
avg_mse += mse.data[0]
print("===>Avg. Loss: {:.4f}".format(avg_mse/len(valDataloader)))
def checkpoint(epoch):
model_out_path = "./model_pretrained/AOD_net_epoch_relu_{}.pth".format(epoch)
torch.save(net, model_out_path)
print("Checkpoint saved to {}".format(model_out_path))train 函数用于训练模型,计算损失并更新模型参数。
validate 函数用于验证模型,计算验证集上的平均损失。
checkpoint 函数用于保存模型检查点。
主程序
for epoch in range(1, args.nEpochs + 1):
train(epoch)
validate()
checkpoint(epoch)循环训练和验证模型,每个epoch结束后保存模型检查点。
去雾模型测试
import argparse
import PIL.Image as Image
import scipy.misc
import skimage.io as sio
import torch
import torch.nn.parallel
import torchvision.transforms as transforms
from torch.autograd import Variable
parser = argparse.ArgumentParser()
parser.add_argument('--input_image', type=str, required=True, help='input image to use')
parser.add_argument('--model', type=str, required=True, help='model file to use')
parser.add_argument('--output_filename', type=str, required=True, help='where to save the output image')
parser.add_argument('--cuda', action='store_true', help='use cuda?')
args = parser.parse_args()
print(args)
#===== load model =====
print('===> Loading model')
net = torch.load(args.model)
if args.cuda:
net = net.cuda()
#===== Load input image =====
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean = (0.5, 0.5, 0.5), std = (0.5, 0.5, 0.5))
]
)
img = Image.open(args.input_image).convert('RGB')
imgIn = transform(img).unsqueeze_(0)
#===== Test procedures =====
varIn = Variable(imgIn)
if args.cuda:
varIn = varIn.cuda()
prediction = net(varIn)
prediction = prediction.data.cpu().numpy().squeeze().transpose((1,2,0))
scipy.misc.toimage(prediction).save(args.output_filename)通过加载预训练模型、对输入图像进行预处理、进行推理并保存结果,最终生成去雾后的图像。
若仅使用CPU进行模型测试,则只需要修改测试文件中的
net = torch.load(args.model) 修改为 net = torch.load(args.model,map_location={'cuda:0': 'cpu'})
结果






基于C2P-Net的深度学习去雾
实验原理
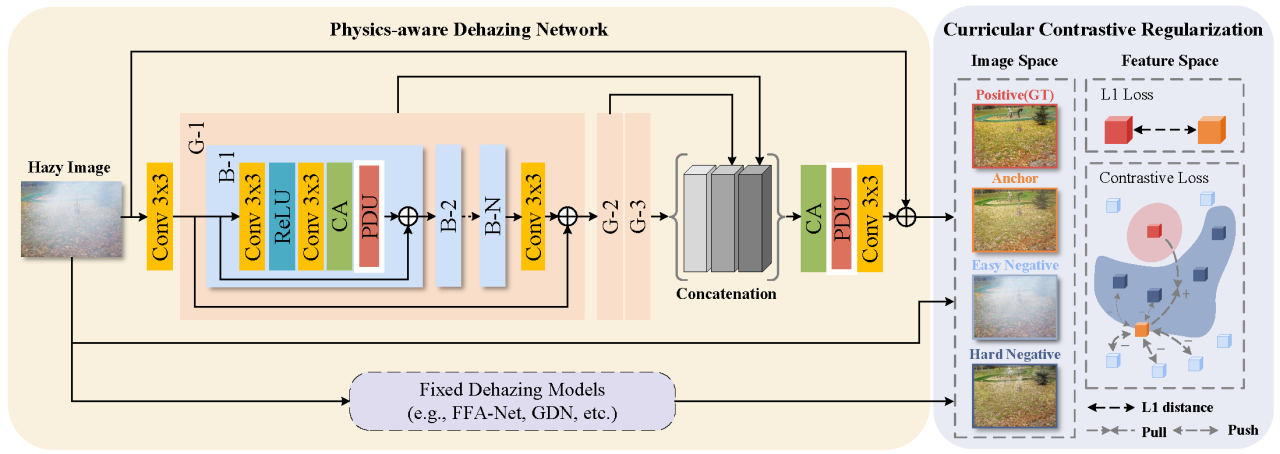
物理感知双分支单元
设计背景:传统的单张图像去雾方法要么在原始空间直接估计未知因素(传输图和大气光),要么在特征空间中忽略这些物理特性。为了结合物理模型的优势并避免累积误差,设计了PDU。
原理:基于大气散射模型,PDU将传输图和大气光的估计任务分配给两个并行的分支,每个分支分别学习与相应物理因素相关的特征表示。这样可以更精确地合成符合物理模型的潜在清晰图像。
实现:通过一系列卷积层和非线性激活函数,两个分支各自提取图像特征,然后通过加权求和的方式结合这些特征,最终得到去雾化的图像输出
共识负样本对比正则化
设计背景:为了提高特征空间的可解释性和引导网络学习更有区分度的特征表示,引入了基于对比学习的正则化方法。
原理:对比学习的核心思想是区分正样本对(锚点与其正样本)和负样本对(锚点与其负样本)。在去雾任务中,正样本对是指同一场景下的清晰图像和模糊图像,负样本对则是不同场景下的清晰图像。通过最小化正样本之间的距离和最大化负样本之间的距离,可以约束解决方案的空间,从而提高去雾效果。
实现:在训练过程中,对于每个清晰图像和对应的模糊图像对,网络会学习一个对比损失函数。这个损失函数会随着训练进程动态调整,以平衡正样本和负样本的贡献。具体来说,容易区分的样本(例如,PSNR大于30的样本)会被视为“容易的”样本,而其他样本则被视为“非容易的”样本,并给予更高的权重。这样,网络就会首先学习到容易样本的特征,然后再逐渐聚焦于更难以区分的样本,从而实现一种渐进式的学习策略。
网络整体架构
C2PNet由多个PDU模块串联而成,形成一个多阶段的去雾网络。每个PDU模块负责处理输入图像的不同分辨率版本,从而逐步恢复出高分辨率的清晰图像。在每个PDU模块中,都会对输入图像执行上采样操作,以逐渐重建出全分辨率的清晰图像。
训练策略
除了传统的L1损失用于直接衡量网络预测的去雾图像和真实清晰图像之间的差异外,C2PNet还采用了CR作为正则化手段来提升特征学习的质量。
在训练过程中,网络会为每个清晰图像和其对应的模糊图像对生成对比损失。同时,为了使网络能够从难易程度不同的样本中学习到有效的特征表示,网络会根据样本的难度动态调整对比损失的权重。
程序设计
模型架构
'''
引入必要的库
'''
import sys
import torch
import torch.nn as nn
from torchvision import models
sys.path.append('/')
'''
引入Vgg19模型
requires_grad 参数用于控制是否需要更新模型中的参数,若为false则冻结 不进行梯度计算
'''
class Vgg19(torch.nn.Module):
def __init__(self, requires_grad=False):
super(Vgg19, self).__init__()
vgg_pretrained_features = models.vgg19(pretrained=True).features
self.slice1 = torch.nn.Sequential()
self.slice2 = torch.nn.Sequential()
self.slice3 = torch.nn.Sequential()
self.slice4 = torch.nn.Sequential()
self.slice5 = torch.nn.Sequential()
for x in range(2):
self.slice1.add_module(str(x), vgg_pretrained_features[x])
for x in range(2, 7):
self.slice2.add_module(str(x), vgg_pretrained_features[x])
for x in range(7, 12):
self.slice3.add_module(str(x), vgg_pretrained_features[x])
for x in range(12, 21):
self.slice4.add_module(str(x), vgg_pretrained_features[x])
for x in range(21, 30):
self.slice5.add_module(str(x), vgg_pretrained_features[x])
if not requires_grad:
for param in self.parameters():
param.requires_grad = False
def forward(self, X):
h_relu1 = self.slice1(X)
h_relu2 = self.slice2(h_relu1)
h_relu3 = self.slice3(h_relu2)
h_relu4 = self.slice4(h_relu3)
h_relu5 = self.slice5(h_relu4)
return [h_relu1, h_relu2, h_relu3, h_relu4, h_relu5]
'''
定义一个对比损失模型
self.weights 是用于加权不同层输出特征的系数。
self.ab 用于控制是否启用对比损失的部分功能(可能用于消融实验)
'''
class C2R(nn.Module):
def __init__(self, ablation=False):
super(C2R, self).__init__()
self.vgg = Vgg19().cuda()
self.l1 = nn.L1Loss()
self.weights = [1.0 / 32, 1.0 / 16, 1.0 / 8, 1.0 / 4, 1.0]
self.ab = ablation
print('*******************use normal 6 neg clcr loss****************')
'''
forward 方法计算输入图像 a 和正样本 p、负样本 n1 至 n6 之间的对比损失。
首先,输入图像通过 Vgg19 模型提取特征。
计算正样本和负样本的 L1 损失。
如果 self.ab 为 False,则计算对比损失。对比损失是正样本损失与加权负样本损失的比值。
最后,将不同层的对比损失加权求和,得到总损失。
'''
def forward(self, a, p, n1, n2, n3, n4, n5, n6, inp, weight):
a_vgg, p_vgg, n1_vgg, n2_vgg, n3_vgg, n4_vgg, n5_vgg, n6_vgg = self.vgg(a), self.vgg(p), self.vgg(n1), self.vgg(
n2), self.vgg(n3), self.vgg(n4), self.vgg(n5), self.vgg(n6)
inp_vgg = self.vgg(inp)
n1_weight, n2_weight, n3_weight, n4_weight, n5_weight, n6_weight, inp_weight = weight
loss = 0
for i in range(len(a_vgg)):
d_ap = self.l1(a_vgg[i], p_vgg[i].detach())
if not self.ab:
d_an1 = self.l1(a_vgg[i], n1_vgg[i].detach())
d_an2 = self.l1(a_vgg[i], n2_vgg[i].detach())
d_an3 = self.l1(a_vgg[i], n3_vgg[i].detach())
d_an4 = self.l1(a_vgg[i], n4_vgg[i].detach())
d_an5 = self.l1(a_vgg[i], n5_vgg[i].detach())
d_an6 = self.l1(a_vgg[i], n6_vgg[i].detach())
d_inp = self.l1(a_vgg[i], inp_vgg[i].detach())
contrastive = d_ap / (
d_an1 * n1_weight + d_an2 * n2_weight + d_an3 * n3_weight + d_an4 * n4_weight + d_an5 * n5_weight + d_an6 * n6_weight + d_inp * inp_weight + 1e-7)
else:
contrastive = d_ap
loss += self.weights[i] * contrastive
return loss模型训练
import time
import warnings
from tensorboardX import SummaryWriter
from torch import optim
from torch.backends import cudnn
from C2R import C2R
from data_utils import *
from models.C2PNet import *
from option import model_name, log_dir
warnings.filterwarnings('ignore')
print('log_dir :', log_dir)
print('model_name:', model_name)
models_ = {
'C2PNet': C2PNet(gps=opt.gps, blocks=opt.blocks),
}
loaders_ = {
'its_train': ITS_train_loader_lmdb,
'its_test': ITS_test_loader,
'ots_test': OTS_test_loader,
# 'ots_train': OTS_train_loader_all,
}
start_time = time.time()
T = opt.steps
cl_lambda = opt.cl_lambda
def lr_schedule_cosdecay(t, T, init_lr=opt.lr):
lr = 0.5 * (1 + math.cos(t * math.pi / T)) * init_lr
return lr
def curriculum_weight(difficulty):
if opt.testset == 'OTS_test':
diff_list = [17.43, 18.12, 30.86, 31.98, 32.98, 33.57] # OTS
else:
diff_list = [17, 19, 31, 32, 36, 40]
weights = [(1 + cl_lambda) if difficulty > x else (1 - cl_lambda) for x in diff_list]
weights.append(len(diff_list))
new_weights = [i / sum(weights) for i in weights]
return new_weights
def clcr_train(train_model, train_loader, test_loader, optim, criterion):
losses = []
start_step = 0
max_ssim = 0
max_psnr = 0
best_psnr = 0
ssims = []
psnrs = []
initial_loss_weight = opt.loss_weight
if opt.resume and os.path.exists(opt.model_dir):
print(f'resume from {opt.model_dir}')
ckp = torch.load(opt.model_dir)
print(opt.best_model_dir)
losses = ckp['losses']
start_step = ckp['step']
max_ssim = ckp['max_ssim']
max_psnr = ckp['max_psnr']
psnrs = ckp['psnrs']
ssims = ckp['ssims']
weights = curriculum_weight(best_psnr)
print(f'start_step:{start_step} start training ---')
else:
weights = curriculum_weight(0)
print('train from scratch *** ')
print(
f'n1_weight:{weights[0]}| n2_weight:{weights[1]}| n3_weight:{weights[2]}| n4_weight:{weights[3]}| n5_weight:{weights[4]}|n6_weight:{weights[5]}|inp_weight:{weights[6]}')
for step in range(start_step + 1, opt.steps + 1):
train_model.train()
lr = opt.lr
if not opt.no_lr_sche:
lr = lr_schedule_cosdecay(step, T)
for param_group in optim.param_groups:
param_group["lr"] = lr
x, y, n1, n2, n3, n4, n5, n6, inp = next(iter(train_loader))
x = x.to(opt.device)
y = y.to(opt.device)
n1 = n1.to(opt.device)
n2 = n2.to(opt.device)
n3 = n3.to(opt.device)
n4 = n4.to(opt.device)
n5 = n5.to(opt.device)
n6 = n6.to(opt.device)
out = train_model(x)
pixel_loss = criterion[0](out, y)
loss2 = 0
if opt.clcrloss:
loss2 = criterion[1](out, y, n1, n2, n3, n4, n5, n6, x, weights)
loss = pixel_loss + opt.loss_weight * loss2
loss.backward()
if opt.clip:
torch.nn.utils.clip_grad_norm_(train_model.parameters(), 0.2)
optim.step()
optim.zero_grad()
for param in train_model.parameters():
param.grad = None
losses.append(loss.item())
print(
f'\rpixel loss : {pixel_loss.item():.5f}| cr loss : {opt.loss_weight * loss2.item():.5f}| step :{step}/{opt.steps}|lr :{lr :.7f} |time_used :{(time.time() - start_time) / 60 :.1f}',
end='', flush=True)
if step % opt.eval_step == 0:
opt.loss_weight = initial_loss_weight
with torch.no_grad():
ssim_eval, psnr_eval = test(train_model, test_loader)
print(f'\nstep :{step} |ssim:{ssim_eval:.4f}| psnr:{psnr_eval:.4f}')
with SummaryWriter(logdir=log_dir, comment=log_dir) as writer:
writer.add_scalar('data/ssim', ssim_eval, step)
writer.add_scalar('data/psnr', psnr_eval, step)
writer.add_scalars('group', {
'ssim': ssim_eval,
'psnr': psnr_eval,
'loss': loss
}, step)
ssims.append(ssim_eval)
psnrs.append(psnr_eval)
torch.save({
'step': step,
'ssims': ssims,
'psnrs': psnrs,
'losses': losses,
'model': train_model.state_dict(),
'weight': weights
}, opt.latest_model_dir)
if ssim_eval > max_ssim and psnr_eval > max_psnr:
max_ssim = max(max_ssim, ssim_eval)
max_psnr = max(max_psnr, psnr_eval)
weights = curriculum_weight(max_psnr)
torch.save({
'step': step,
'max_psnr': max_psnr,
'max_ssim': max_ssim,
'ssims': ssims,
'psnrs': psnrs,
'losses': losses,
'model': train_model.state_dict(),
'weight': weights
}, opt.model_dir)
print(f'\n model saved at step :{step}| max_psnr:{max_psnr:.4f}|max_ssim:{max_ssim:.4f}')
print(
f'n1_weight:{weights[0]}| n2_weight:{weights[1]}| n3_weight:{weights[2]}| n4_weight:{weights[3]}| n5_weight:{weights[4]}|n6_weight:{weights[5]}|inp_weight:{weights[6]}')
np.save(f'./numpy_files/{model_name}_{opt.steps}_losses.npy', losses)
np.save(f'./numpy_files/{model_name}_{opt.steps}_ssims.npy', ssims)
np.save(f'./numpy_files/{model_name}_{opt.steps}_psnrs.npy', psnrs)
def test(test_model, loader_test):
test_model.eval()
torch.cuda.empty_cache()
ssims = []
psnrs = []
for i, (inputs, targets) in enumerate(loader_test):
inputs = inputs.to(opt.device)
targets = targets.to(opt.device)
pred = test_model(inputs)
ssim1 = ssim(pred, targets).item()
psnr1 = psnr(pred, targets)
ssims.append(ssim1)
psnrs.append(psnr1)
return np.mean(ssims), np.mean(psnrs)
if __name__ == "__main__":
loader_train = loaders_[opt.trainset]
loader_test = loaders_[opt.testset]
net = models_[opt.net]
net = net.to(opt.device)
pytorch_total_params = sum(p.nelement() for p in net.parameters() if p.requires_grad)
print("Total_params: ==> {}".format(pytorch_total_params / 1e6))
if opt.device == 'cuda':
net = torch.nn.DataParallel(net)
cudnn.benchmark = True
criterion = [nn.L1Loss().to(opt.device)]
optimizer = optim.Adam(params=filter(lambda x: x.requires_grad, net.parameters()), lr=opt.lr, betas=(0.9, 0.999),
eps=1e-08)
optimizer.zero_grad()
if opt.clcrloss:
criterion.append(C2R().to(opt.device))
clcr_train(net, loader_train, loader_test, optimizer, criterion)
1. 引入必要库和模块
代码首先导入了所需的库和模块,包括 PyTorch、TensorBoard、优化器等,以及自定义的模型和数据加载模块。
2. 模型和数据加载器初始化
通过字典 models_ 和 loaders_ 定义了可用的模型和数据加载器。根据配置选项 opt 初始化模型参数和数据加载器。
3. 学习率调度和权重计算
定义了一个余弦退火学习率调度函数 lr_schedule_cosdecay 和一个课程学习权重计算函数 curriculum_weight,用于动态调整学习率和权重。
4. 训练函数
定义了核心的训练函数 clcr_train,其中包括以下步骤:
读取和加载数据。
计算像素损失和对比损失。
通过反向传播更新模型参数。
定期评估模型性能,并将评估结果记录到 TensorBoard 中。
保存模型和损失、评估指标等中间结果。
5. 测试函数
定义了一个 test 函数,用于在测试数据集上评估模型性能,计算 SSIM 和 PSNR 指标。
6. 主程序入口
程序的主入口主要执行以下步骤:
加载训练和测试数据。
初始化模型,并将模型移动到指定设备(如 GPU)。
定义损失函数和优化器。
调用 clcr_train 函数开始训练。
模型测试
import argparse
import os
import numpy as np
import torch
import torchvision.transforms as tfs
import torchvision.utils as vutils
from PIL import Image
from tqdm import tqdm
from metrics import psnr, ssim
from models.C2PNet import C2PNet
parser = argparse.ArgumentParser()
parser.add_argument('-d', '--dataset_name', help='name of dataset', choices=['indoor', 'outdoor'],
default='indoor')
parser.add_argument('--save_dir', type=str, default='dehaze_images', help='dehaze images save path')
parser.add_argument('--save', action='store_true', help='save dehaze images')
opt = parser.parse_args()
dataset = opt.dataset_name
if opt.save:
if not os.path.exists(opt.save_dir):
os.mkdir(opt.save_dir)
output_dir = os.path.join(opt.save_dir, dataset)
print("pred_dir:", output_dir)
if not os.path.exists(output_dir):
os.mkdir(output_dir)
if dataset == 'indoor':
haze_dir = 'data/SOTS/indoor/hazy/'
clear_dir = 'data/SOTS/indoor/clear/'
model_dir = 'trained_models/ITS.pkl'
elif dataset == 'outdoor':
haze_dir = 'data/SOTS/outdoor/hazy/'
clear_dir = 'data/SOTS/outdoor/clear/'
model_dir = 'trained_models/OTS.pkl'
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
net = C2PNet(gps=3, blocks=19)
ckp = torch.load(model_dir)
net = net.to(device)
net.load_state_dict(ckp['model'])
net.eval()
psnr_list = []
ssim_list = []
for im in tqdm(os.listdir(haze_dir)):
haze = Image.open(os.path.join(haze_dir, im)).convert('RGB')
if dataset == 'indoor' or dataset == 'outdoor':
clear_im = im.split('_')[0] + '.png'
else:
clear_im = im
clear = Image.open(os.path.join(clear_dir, clear_im)).convert('RGB')
haze1 = tfs.ToTensor()(haze)[None, ::]
haze1 = haze1.to(device)
clear_no = tfs.ToTensor()(clear)[None, ::]
with torch.no_grad():
pred = net(haze1)
ts = torch.squeeze(pred.clamp(0, 1).cpu())
pp = psnr(pred.cpu(), clear_no)
ss = ssim(pred.cpu(), clear_no)
psnr_list.append(pp)
ssim_list.append(ss)
if opt.save:
vutils.save_image(ts, os.path.join(output_dir, im))
print(f'Average PSNR is {np.mean(psnr_list)}')
print(f'Average SSIM is {np.mean(ssim_list)}')设置路径后即可完成对图像的去雾处理



